



Les IA génératives telles que ChatGPT reposent sur des modèles entraînés à partir de grandes quantités de données, capturant un état du monde figé à une date précise—juin 2024 dans le cas de GPT-4o. Cette architecture, dite « stateless », n’a pas de mémoire intrinsèque et ne peut donc pas fournir spontanément des réponses actualisées.
Pour offrir des réponses pertinentes sur des sujets récents ou évolutifs, ces modèles doivent utiliser des mécanismes complémentaires appelés « Tools ». Depuis peu, cette capacité d’accéder en temps réel à des données externes s’expose également via une nouvelle approche, les Model Context Protocol (MCP), facilitant l’ajout de “super pouvoirs” aux LLMs.

⚖️Un problème de Droit
Explorer librement le web pour alimenter les IA n’est pas légalement anodin. Tout crawler doit en premier lieu respecter le fichier robots.txt, qui définit les limites fixées par chaque éditeur.
En Europe, une contrainte supplémentaire s’applique désormais : l’EU Opt-out, récemment validé par la jurisprudence dans l’affaire Kneschke vs LAION (Allemagne, 2023). Ce mécanisme permet d’interdire explicitement aux outils qui font du scraping à des fins de machine learning d’aspirer des contenus protégés par le droit d’auteur, lui-même riche en subtilités pour bien faire les choses.
Par ailleurs, même les requêtes dites « éphémères » — celles qui visent à enrichir temporairement la réponse ou la recommandation d’un LLM — restent encadrées. Elles doivent respecter des conditions précises, dont l’interdiction de réutilisation ou d’exploitation commerciale (« Not for redistribution or commercial use »), souvent inscrite dans les CGU des services interrogés.
💰Un enjeux de Business
Le LLM se positionne désormais comme un tiers de confiance entre l’utilisateur et la connaissance. Il ne se contente plus de remplacer le moteur de recherche : il synthétise, reformule et délivre une réponse directe, avec l’autorité apparente d’un expert.
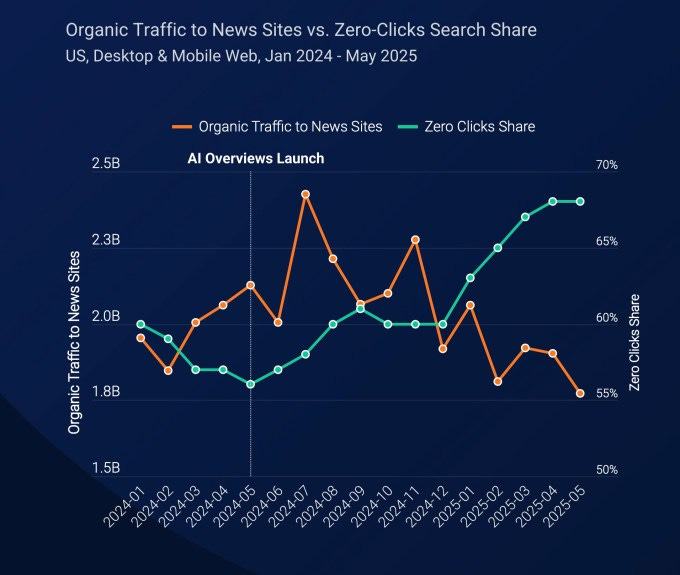
Conséquence directe : une chute exponentielle des consultations sur les sites qui partagent du savoir, un phénomène mesuré par des outils comme SimilarWeb. Stack Overflow, déjà affaibli par l’émergence des IA capables de coder, en a été l’un des premiers exemples.
Mais l’impact dépasse largement les communautés bénévoles. Aujourd’hui, même les sites éditoriaux ou professionnels — dont le modèle repose sur la publicité ou l’abonnement, comme le Wall Street Journal — voient leur audience fondre. C’est l’économie entière du web de la connaissance qui vacille.
Une renaissance du web
Google a tenté l’approche des OfferWalls, proposant des micro‑paywalls avec paiement à l’acte. Mais cette logique se heurte à un obstacle majeur : l’utilisateur final refuse massivement le micro‑paiement.
Le 11 août 2025, Microsoft mettra fin à son API Bing, longtemps utilisée par des scrapers pour collecter des données. Elle sera remplacée par une offre orientée « Agents », conçue — à mon sens — pour mieux répondre aux enjeux juridiques, mais au prix d’une moindre précision.

La solution qui pourrait, selon moi, marquer un tournant comparable à celui des réseaux sociaux en 2006, c’est celle du Pay‑Per‑Crawl proposée par Cloudflare. Jusqu’ici, Cloudflare permettait surtout de bloquer ou filtrer les bots. Mais bloquer tout accès, c’est aussi renoncer au référencement naturel. Le Pay‑Per‑Crawl introduit une logique simple : Allow / Charge / Block. Chaque bot pourra accéder au contenu… à condition de payer.
Je crois profondément en ce modèle. Comme Netflix pour la vidéo ou Spotify pour la musique, ChatGPT et les LLM deviendront les agrégateurs de la connaissance… mais cette fois, avec une juste rétribution des créateurs et experts.
Des enjeux de taille
Depuis la publication du billet de blog (merci Ari !), nous enchaînons, avec Élise Dufour, les discussions avec Cloudflare, OpenAI, des éditeurs de presse et bien d’autres acteurs.
J’en ai même profité pour mettre à jour ma formation IA‑no‑bullshit à destination des décideurs, afin de vulgariser ces enjeux complexes et aider à prendre les bonnes décisions
(📣contactez-nous si intéressé).
➡️ Car dès qu’il y a paiement, il y a contrat : de vente, d’usage, de licence… avec un cadre juridique clair, adapté à la nature des données échangées. Bien plus robuste que ces pseudo‑normes où un robot serait censé interpréter des CGU rédigées pour des humains — ce que beaucoup d’acteurs du secteur appellent de leurs vœux.
➡️ Ce cadre ouvre surtout la voie à de nouvelles mécaniques : tarification dynamique, enchères, optimisation SEO, autant d’outils pour redéfinir l’économie de l’accès à la connaissance.
Vers l’infini et l’au-delà
Ce n’est que le début de l’histoire. Aujourd’hui, Cloudflare ne gère qu’environ 20 % du trafic mondial, et tout reste à construire. Le concept du Pay‑Per‑Crawl comporte encore des angles morts… (j’ai plein d’idées) mais s’il venait à se généraliser, les perspectives seraient immenses.
1️⃣ Une voie saine pour monétiser la connaissance, tout en asséchant naturellement les sources toxiques : générateurs de fake news, fermes à contenu, spam. Avec une vraie logique contractuelle combiné avec steganographie ou watermarking.
2️⃣ Un modèle étendable au‑delà du scraping, comme un prolongement logique des API monétisées — sauf que cette fois, le LLM endosserait et gérerait le coût. Cela exigerait sans doute de faire évoluer le protocole MCP.
3️⃣ Même les contenus générés par les utilisateurs, comme les commentaires ou contributions, pourraient entrer dans cette logique. Car toute valeur a un prix — un filtre naturel qui pourrait assainir le web.
Conclusion
✅ C’est clairement l’un de mes sujets chauds de cet été. Si vous cherchez un accompagnement sérieux — technique ET juridique — au plus près des acteurs qui font bouger les lignes, contactez-moi.
🚫En revanche, si c’est pour débattre d’AGI ou autres punchlines d’influenceurs, 👈swipe gauche, merci. Je vois déjà venir ceux qui rebaptiseront ça “Web 5.0” ou “6.0” juste pour occuper l’espace…
Edit : 18/07/2025
Voici un excellent article de Ben Thomson dans Stratchery (version ChatGPT) dans lequel il confirme la même théorie en évoquant un passage du Web publicitaire vers un Web agentique et payant.